搜索到
15
篇与
的结果
-
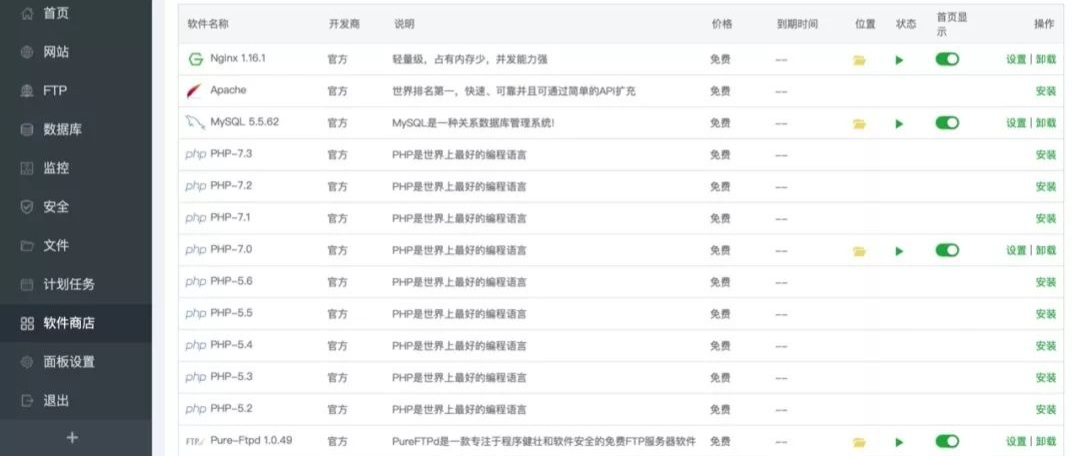
 Linux宝塔面板解决php-fpm占用CPU过高全记录 宝塔面板实际上也很实用,但是随着我认真做站的程度,突然发现网站越来越卡,基本上达到无法使用的状态,无法访问(502)的时间甚至达到了几个小时。这种情况严重干扰了我的做站热情和我的用户们的心情,这让我不得不去寻找究竟是什么原因。开始的时候我怀疑因为我设置的弱密码导致被攻击了,或者系统以及“被挖矿”了,对于我这种半吊子的个人站长来说在日志里真的也查不到什么有用的信息。于是乎祭出大杀器:重装系统。重装系统这个杀器我是跟我大学室友学的,反正他每次电脑遇到什么情况都是装系统。哈哈哈哈,继续说回来。昨天真是装系统、装环境、转移网站各种眼花缭乱的操作之后还是解决不了什么问题。后来又怀疑是mysql版本的问题,初始我装的mysql版本是5.5的,top命令发现mysql占用内存过大,于是就换到5.1。来来回回装了大概有6次,还是解决不了问题。简直无奈了,一度怀疑是服务器配置太低都准备入手高配了,但是还是不死心。今天早上突然又开始502了,top命令盯着一早上,突然发现php-fpm占用内存奇高无比。有门,也许杀死这个进程就能够解决问题了。搜索一通发现果真是php-fpm的问题。记录一下解决过程,希望下次遇到同类问题就不会束手无策了。解决方案1、通过宝塔面板安装的建站环境是LNMP,使用的Nginx 1.16.1、MySQL 5.5.62、PHP-7.0。2、优化PHP7.0设置。按下图操作先进入到PHP7.0管理页面。首先先安装一个opcache缓冲器,用于加速PHP脚本,其他的就都按默认的来吧,毕竟安装的扩展太多容易影响性能。修改max_execution_time时间为20.性能调整。这里大家可以根据自己服务器配置进行设置,宝塔面板比较人性化,会根据你的服务器配置设置推荐方案。其实设置并发多少,大家可以根据自己服务器内存大小进行计算,一般一个php-fpm进程占用内存30M左右,以1024MB内存(1G内存)来计算,大概可以设置34个并发。我使用的就是1核1G内存配置的服务器,安装宝塔面板后推荐的是40并发,但我觉得自己根本用不到那么高的并发,所以设置了20并发的方案,并把max_spare_servers数字调整成了14.我按照上面操作后,发现服务器CPU不像之前一样经常性占用100%了,虽然php-fpm有时候还会出现突发占用CPU 100%的情况,但基本很快就会恢复正常,对用户的浏览不会造成过多的影响。分析原因的话不知道是不是兼容性问题,因为我个人对这些东西没有过多的研究,只是恰巧碰到运气而已吧,说得不对的地方请大佬们指正。-END-
Linux宝塔面板解决php-fpm占用CPU过高全记录 宝塔面板实际上也很实用,但是随着我认真做站的程度,突然发现网站越来越卡,基本上达到无法使用的状态,无法访问(502)的时间甚至达到了几个小时。这种情况严重干扰了我的做站热情和我的用户们的心情,这让我不得不去寻找究竟是什么原因。开始的时候我怀疑因为我设置的弱密码导致被攻击了,或者系统以及“被挖矿”了,对于我这种半吊子的个人站长来说在日志里真的也查不到什么有用的信息。于是乎祭出大杀器:重装系统。重装系统这个杀器我是跟我大学室友学的,反正他每次电脑遇到什么情况都是装系统。哈哈哈哈,继续说回来。昨天真是装系统、装环境、转移网站各种眼花缭乱的操作之后还是解决不了什么问题。后来又怀疑是mysql版本的问题,初始我装的mysql版本是5.5的,top命令发现mysql占用内存过大,于是就换到5.1。来来回回装了大概有6次,还是解决不了问题。简直无奈了,一度怀疑是服务器配置太低都准备入手高配了,但是还是不死心。今天早上突然又开始502了,top命令盯着一早上,突然发现php-fpm占用内存奇高无比。有门,也许杀死这个进程就能够解决问题了。搜索一通发现果真是php-fpm的问题。记录一下解决过程,希望下次遇到同类问题就不会束手无策了。解决方案1、通过宝塔面板安装的建站环境是LNMP,使用的Nginx 1.16.1、MySQL 5.5.62、PHP-7.0。2、优化PHP7.0设置。按下图操作先进入到PHP7.0管理页面。首先先安装一个opcache缓冲器,用于加速PHP脚本,其他的就都按默认的来吧,毕竟安装的扩展太多容易影响性能。修改max_execution_time时间为20.性能调整。这里大家可以根据自己服务器配置进行设置,宝塔面板比较人性化,会根据你的服务器配置设置推荐方案。其实设置并发多少,大家可以根据自己服务器内存大小进行计算,一般一个php-fpm进程占用内存30M左右,以1024MB内存(1G内存)来计算,大概可以设置34个并发。我使用的就是1核1G内存配置的服务器,安装宝塔面板后推荐的是40并发,但我觉得自己根本用不到那么高的并发,所以设置了20并发的方案,并把max_spare_servers数字调整成了14.我按照上面操作后,发现服务器CPU不像之前一样经常性占用100%了,虽然php-fpm有时候还会出现突发占用CPU 100%的情况,但基本很快就会恢复正常,对用户的浏览不会造成过多的影响。分析原因的话不知道是不是兼容性问题,因为我个人对这些东西没有过多的研究,只是恰巧碰到运气而已吧,说得不对的地方请大佬们指正。-END- -
CentOS/RHEL Linux安装EPEL第三方软件源 EPEL(Extra Packages for Enterprise Linux) 是由 Fedora 社区打造,为 RHEL 及衍生发行版如 CentOS等提供高质量软件包的项目。装上了 EPEL,就像在 Fedora 上一样,可以通过 yum install 软件包名,即可安装很多以前需要编译安装的软件、常用的软件或一些比较流行的软件,比如现在流行的nginx、htop、ncdu、vnstat、axel、cmake3、libsodium-devel等等软件包/依赖包,都可以使用EPEL很方便的安装更新。安装EPEL源目前可以直接通过执行命令: yum install epel-release 直接进行安装如果服务器或VPS是在国内,可以设置为国内的源,执行命令:sed -i "s@^#baseurl=http://download.fedoraproject.org/pub@baseurl=http://mirrors.aliyun.com@g" /etc/yum.repos.d/epel*.repo sed -i "s@^metalink@#metalink@g" /etc/yum.repos.d/epel*.repo{alert type="warning"}如果是CentOS 8,请务必将前面两条命令里面的http都改成https。{/alert}如果前面命令无法安装 epel-release 可以尝试以下方法CentOS/RHEL 5 :rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-5.noarch.rpmCentOS/RHEL 6 :rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-6.noarch.rpmCentOS/RHEL 7 :rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm###CentOS/RHEL 8 : rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm Ok,如果不报错的话,epel源就安装完毕。使用EPEL源安装软件现在就可以执行:yum install 软件包名进行安装了,nginx、htop、ncdu、vnstat等等一些常用的软件都灰常简单的装上了。心动了吧赶快试试吧。
-
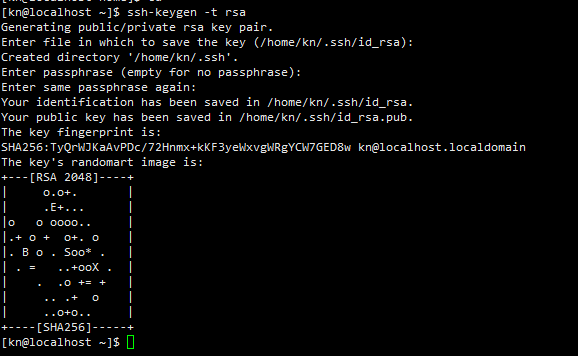
centos7 配置使用证书登录 1.切换到需要使用证书登陆的用户2.生成证书 -t 指定使用的加密方法ssh-keygen -t rsa3.将公钥写入到authorized_keyscat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys4.设置权限,很重要chmod 600 /root/.ssh/authorized_keys chmod -R 700 /root/.ssh5.修改sshd_config 配置文件,编辑该文件,需要root权限,然后重启sshdvim /etc/ssh/sshd_config修改前:修改为:重启SSHsystemctl restart sshd6.下载私钥,使用xshell登陆7.关闭密码登陆vim /etc/ssh/sshd_config修改前:修改为:重启SSHsystemctl restart sshd8.授权多个服务器使用该证书登陆,要确保都有同一个用户直接将刚刚生成的id_rsa_pub 追加到需要授权登陆的服务器中的aurhorized_keys需要提示 该证书未在远程计算机上注册,有两种可能1.没有追加成功2.authorized_keys的权限必须是600
-
魔方云扩容磁盘障处理:磁盘扩容出错:e2fsck: Bad magic number in super-block while trying to open /dev/vdb1 1.故障现象及分析按照阿里云官网教程对云服务器进行磁盘扩容,使用 fdisk 重新分区,最后使用 e2fsck 和 resize2fs 来完成文件系统层面的扩容,在执行“e2fsck -f /dev/vdb1”命令时报错,如果你的问题和下面的错误一样,可以接着往下看[root@zuiyoujie ~]# e2fsck -f /dev/vdb1 e2fsck 1.41.12 (17-May-2010) e2fsck: Superblock invalid, trying backup blocks... e2fsck: Bad magic number in super-block while trying to open /dev/vdb1 The superblock could not be read or does not describe a correct ext2 filesystem. If the device is valid and it really contains an ext2 filesystem (and not swap or ufs or something else), then the superblock is corrupt, and you might try running e2fsck with an alternate superblock: e2fsck -b 8193 <device>按照提示执行“e2fsck -b 8193 /dev/vdb1”,并没有什么用根据报错信息推测是该工具并没有找到 super-block,也就是分区起始位置有问题1.1.故障分析查看当前磁盘分区信息[root@zuiyoujie ~]# fdisk -l Disk /dev/vda: 53.7 GB, 53687091200 bytes 255 heads, 63 sectors/track, 6527 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00078f9c Device Boot Start End Blocks Id System /dev/vda1 * 1 6527 52426752 83 Linux Disk /dev/vdb: 536.9 GB, 536870912000 bytes 2 heads, 10 sectors/track, 52428800 cylinders Units = cylinders of 20 * 512 = 10240 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x63c3e6e0 Device Boot Start End Blocks Id System /dev/vdb1 103 52428800 524286976 83 Linux # 分区起始位置在103,很重要,需要记录确认当前磁盘分区 /dev/vdb1 的起始位置(起始柱面)在 103 处默认起始柱面应该是像上面 /dev/vda1 分区以 1 开始,或者是常见的 2048,大多数人不会随意指定类似这样的起始柱面之前分区我创建分区必定是 1,但是扩容后就变了,这个应该是导致故障的原因,推测可能阿里云的磁盘扩容可能出问题了,不过这个不重要1.2.解决思路提阿里云工单得到的结果是,用 testdisk 进行数据恢复,显然这个不是我要的方法这个只是分区表损坏,数据并没有丢,处理好分区表即可参考 网络大神 的思路进行解决,并重新重新整理下供大家参考2.故障处理以下操作注意数据备份!!!在 parted 交互式分区工具中执行2.1.使用 parted 工具读取磁盘分区表信息# 我在阿里云控制台扩展的分区大小为 1024 GB parted /dev/vdb --------------------------- [root@zuiyoujie ~]# parted /dev/vdb GNU Parted 2.1 Using /dev/vdb Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) help # 获取帮助信息 align-check TYPE N check partition N for TYPE(min|opt) alignment help [COMMAND] print general help, or help on COMMAND mklabel,mktable LABEL-TYPE create a new disklabel (partition table) mkpart PART-TYPE [FS-TYPE] START END make a partition name NUMBER NAME name partition NUMBER as NAME print [devices|free|list,all|NUMBER] display the partition table, available devices, free space, all found partitions, or a particular partition quit exit program rescue START END rescue a lost partition near START and END resizepart NUMBER END resize partition NUMBER rm NUMBER delete partition NUMBER select DEVICE choose the device to edit disk_set FLAG STATE change the FLAG on selected device disk_toggle [FLAG] toggle the state of FLAG on selected device set NUMBER FLAG STATE change the FLAG on partition NUMBER toggle [NUMBER [FLAG]] toggle the state of FLAG on partition NUMBER unit UNIT set the default unit to UNIT version display the version number and copyright information of GNU Parted (parted) p # 查看分区信 Model: Virtio Block Device (virtblk) Disk /dev/vdb: 1100GB # 获取分区容量 Sector size (logical/physical): 512B/512B Partition Table: msdos # 分区表类型 Number Start End Size Type File system Flags 1 5120B 1100GB 1099GB primary # 当前的分区表信息,是不可用的,实际可用的分区容量为 1099GB -----------------2.2.使用 parted 工具删除错误分区表并重建parted 工具默认启动、结束位置,单位都是用容量 kB/MB/GB 单位进行处理通过 unit s 命令定义,默认使用 sectors 定义起始扇区根据之前获取的信息分区起始位置确认是 103 扇区(parted) rm 1 # 删除1号分区 (parted) unit s # 使用扇区号 (parted) rescue 103 1099GB # 恢复分区表 Information: A ext4 primary partition was found at 2048s -> 1048575999s. Do you want to add it to the partition table? # 找到了ext4格式的分区,起始扇区定位到 2048,结束扇区是 1048575999,这个应该是该磁盘分区的扇区信息 Yes/No/Cancel? y # 是否要创建该分区表,也就是恢复旧的分区表 (parted) p # 再次查看分区表信息 Model: Virtio Block Device (virtblk) Disk /dev/vdb: 2147483648s Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 2048s 1048575999s 1048573952s primary ext4 # 可以看到这个是正确的磁盘分区表 (parted) q # 保存退出 Information: You may need to update /etc/fstab.{alert type="warning"}注意:分区表用 parted 工具删除后无法直接使用 fdisk 进行分区,也请不要尝试这样操作{/alert}2.3.使用 parted 工具重新创建新的分区表(魔方云使用fdisk /dev/vdb 删除分区从这里开始,要记住分区开始位置)这里需要注意的是 parted 工具里 END 的值,由于磁盘的扇区数量不方便确定,可以使用容量来替代[root@zuiyoujie ~]# parted /dev/vdb GNU Parted 2.1 Using /dev/vdb Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) p Model: Virtio Block Device (virtblk) Disk /dev/vdb: 1100GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 537GB 537GB primary ext4 # 重新打开后发现分区表的以容量信息进行展示,可以看出是以前的分区表(未扩容前) (parted) rm 1 # 删除旧的分区表 (parted) p Model: Virtio Block Device (virtblk) Disk /dev/vdb: 1100GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags (parted) unit s (parted) mkpart primary ext4 2048 1099GB # 创建新的分区表,注意要使用前文获取的扇区起始位置2048 (parted) p Model: Virtio Block Device (virtblk) Disk /dev/vdb: 2147483648s Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 2048s 2146484223s 2146482176s primary ext4 # 新的分区表 (parted) q Information: You may need to update /etc/fstab.此时新的分区表就创建成功了需要注意:目前的分区表是使用的 parted 工具创建的分区表!!!2.4.使用 fdisk 工具进行分区如果想使用 fdisk 进行分区,可以在 fdisk 中使用 2048 起始扇区进行操作,注意数据备份!!!重新检查磁盘分区,确认可以正常执行检查文件系统的操作[root@zuiyoujie ~]# e2fsck -f /dev/vdb1 e2fsck 1.41.12 (17-May-2010) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/vdb1: 237246/32768000 files (75.3% non-contiguous), 112383325/131071744 blocks2.5.继续扩容操作可以正常执行确认变更文件系统大小的操作,执行完即可挂载使用[root@zuiyoujie ~]# resize2fs /dev/vdb1 resize2fs 1.41.12 (17-May-2010) Resizing the filesystem on /dev/vdb1 to 268310272 (4k) blocks. The filesystem on /dev/vdb1 is now 268310272 blocks long.2.6.使用工具检查分区表状态parted 工具检查分区表信息[root@zuiyoujie ~]# parted /dev/vdb GNU Parted 2.1 Using /dev/vdb Welcome to GNU Parted! Type 'help' to view a list of commands. (parted) p Model: Virtio Block Device (virtblk) Disk /dev/vdb: 1100GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 1099GB 1099GB primary ext4fdisk 工具检查分区表信息[root@zuiyoujie ~]# fdisk -l Disk /dev/vda: 53.7 GB, 53687091200 bytes 255 heads, 63 sectors/track, 6527 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x00078f9c Device Boot Start End Blocks Id System /dev/vda1 * 1 6527 52426752 83 Linux Disk /dev/vdb: 1099.5 GB, 1099511627776 bytes 255 heads, 63 sectors/track, 133674 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x000ead8a Device Boot Start End Blocks Id System /dev/vdb1 1 133613 1073241088 83 Linux
-
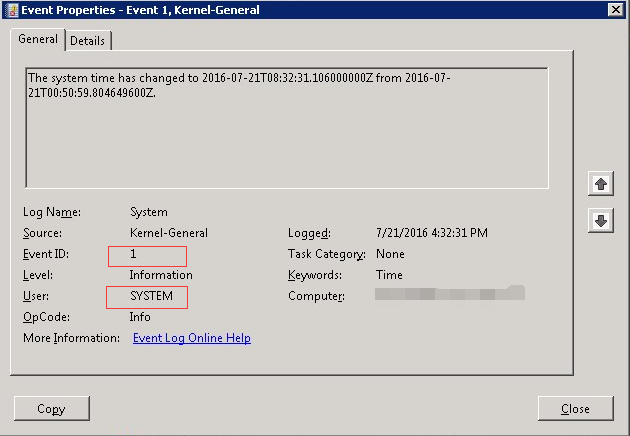
Windows服务器时间不断修改(时间不同步已解决) 一台域内的服务器时间不停地被修改,我先向用户收集了一些信息只有这一台出现此问题,其他服务器均为正常(补充一下,问题快解决完的时候用户告诉我一个重要的消息,就是时间被修改了一段时间后自动会被修改回去)系统版本\服务器用途(考虑是否有软件会造成此问题)\日志信息\是否为虚拟机1.系统版本是Server 2008 数据中心版2.用途就是一台做图的服务器3.日志信息如下图,这个日志是系统日志,事件ID为1,时间从2016-7-21 00:50:59 被改为2016-07-21 08:32:314.是Vmware虚拟机5.注意了,是时间一直被修改,而且日志中的源也判断不出是谁修改了时间= = 第一天1)确定服务器的时间服务是否为正常启动2)查看虚拟机是否和Esxi主机进行了时间同步,没有勾选的话不会和Esxi主机进行时间同步3)因为用户的并不是管理域的,我让用户询问了一下DC的IP地址,然后使用net time进行时间同步之前处理过一个问题也是时间不同步,使用了net time后就好了,net time \ip或者计算机名称 /set即可,会立马同步时间= = 第二天1)第二天用户告诉我时间又被更改了,结合上次的时间更改间隔,其实时间更改是具有规律性的,每7小时41分钟左右就会进行更改2)其实net time这条命令非常的鸡肋!想要更好地解决方法还需要借助w32tm命令在这台服务器上运行命令,查看此机的NTP服务器列表w32tm /query/peers然后修改NTP服务器列表(双引号中用空格分开)引号中的服务器填写PDC服务器的FQDNw32tm /config /manualpeerlist:"SERVER1-FQDN SERVER2-FQND" /update(这里我设置的是10.138.207.22,FQDN我不能说...)3)运行如下命令,开启debuglog。w32tm/debug /enable /file:c:\w32time.log /size:10000000 /entries:0-116Debug日志可以查看到服务器到底从哪里同步的时间另外,如果要更改Debug日志路径的话,可以更改注册表的值HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Config= = 第三天1)时间接着又被修改,之前开启的Debug日志这时候便起到了作用,打开Debug日志后,找啊找,找到三个IP地址10.142.10.33 新加坡的一台域控 10.138.207.26 北京的一台域控10.138.164.167 本机IPHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\W32Time\Parameters下NtpServer的值是time.windows.com,可能是这个值造成的问题吧,将它改为34(切记这里输入34的FQDN) 2)将此目录下的注册表导出HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\W32Time\进行分析,×××部分标明的地方全部改为0(就是不生效的意思),系统默认是启用读取虚拟机时间的所以需要将其关闭,必须重启计算机才生效,VMICTimeProvider(虚拟机时间提供源)3)使用w32tm /query /configuration 命令查看配置[TimeProviders]NtpClient (Local)DllName:C:\Windows\system32\w32time.dll (Local)Enabled: 1 (Local)InputProvider: 1(Local)CrossSiteSyncFlags:2 (Local)AllowNonstandardModeCombinations:1 (Local)ResolvePeerBackoffMinutes:15 (Local)ResolvePeerBackoffMaxTimes:7 (Local)CompatibilityFlags:2147483648 (Local)EventLogFlags: 1(Local)LargeSampleSkew: 3(Local)SpecialPollInterval:3600 (Local)Type: NT5DS(Local)NtpServer: (Undefined or NotUsed)这个是设置自己为时间服务器,如果你使用之前的w32tm命令设置NtpServer的话,他就会变成你设置的值= = 第四天1)接着分析Debug日志,从日志信息中可以看到服务器有两个时间同步源两个源分别是10.138.207.22 另一个10.142.10.33(新加坡域控)2)10.142.10.33并不是PDC,理论上客户端不应该和它进行时间同步,因为都没有手动指定10.3310.138.207.22,这是我们之前一直指定的时间同步源,于是让用户找人在207.22上运行了netdom query fsmo 查看PDC是否为207.22,结果PDC是10.34,34也是一台新加坡的域控也是PDC,207.22和10.33是一个子域3)时间一直被修改的原因:因为我们设置的时间源是207.22,所以他会向207.22进行同步,但是10.34是我们子域中的PDC主机,域客户端默认都会向PDC进行时间同步= = 最终解决1)难道之前设置34为NTPServer没有生效吗(设置NTPServer)设置一个时间同步源,而自己作为客户端去同步时间源1.w32tm /config /manualpeerlist:PDCFQDN /syncfromflags:manual /reliable:yes /update2.net stop w32time & net start w32time (重启服务)2)查看注册表下值HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\W32Time\Parameters ,看到值已经修改为了PDC的FQDN3)经过几天观察,用户反馈最近几天没有时间被修改的日志,问题得以解决= = 总结1)w32tm /query/peers 查看NTP服务器列表2)netdom query fsmo 确认PDC主机是哪台服务器3)w32tm /config /manualpeerlist:PDCFQDN /syncfromflags:manual /reliable:yes /update修改时间同步源4)w32tm/debug /enable /file:c:\w32time.log /size:10000000 /entries:0-116(开启时间Debug)5)这次问题解决的难点在于系统莫名其妙的有两个时间同步源,所以有时候时间被更改了,一段时间后又发现时间恢复了正常,这时候输入上条命令将PDC设置为NtpServer后重新启动w32time服务如果出现了时间不同步问题,按照以上几点进行排查,相信问题可以得到解决